
Table des matières
- Concrètement, le cloaking c’est quoi ?
- Les différentes techniques de cloaking utilisées en SEO
- Cloaking sur le User Agent : la plus risquée car la moins sophistiquée
- Cloaking sur IP : la plus avancée
- Cloaking VS obfuscation de liens : quelles différences ?
- L’obfuscation, moins dangereuse que le cloaking ?
Google définit le cloaking de la façon suivante :
“Pratique qui consiste à présenter aux internautes des URLs ou un contenu différents de ceux destinés aux moteurs de recherche”
Source : https://cutt.ly/ccruwTN
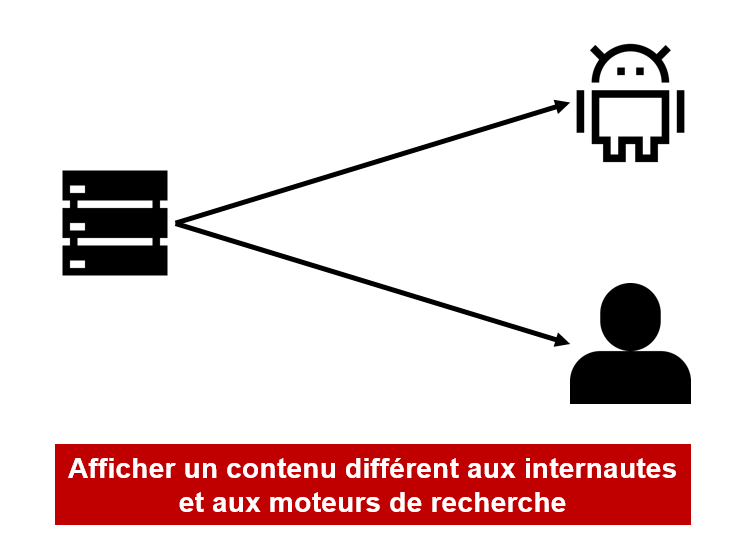
Concrètement, le cloaking c’est quoi ?
Le cloaking, qui signifie “camouflage” en anglais, est en effet une technique SEO, majoritairement utilisée par les Black Hat, qui consiste à afficher un contenu différent selon qu’un internaute ou un robot d’indexation visite une page web. L’objectif visé derrière cette méthode est de tromper le moteur de recherche afin de l’inciter à mieux positionner un site dans son index sur des requêtes stratégiques.
Explication en image du cloaking :
Au-delà de savoir si cette technique est autorisée par Google ou non (la réponse est plutôt non bien entendu !), la question qui se pose souvent c’est :
Existe-t-il des moyens de contourner les règles édictées par Google, ses Guidelines en matière de cloaking, à des fins d’optimisation qui ne présentent pas ou peu de risques de pénalités ?
La question du risque est bien évidemment intrinsèquement liée au cloaking. Ce qui est possible aujourd’hui ne le sera peut-être plus demain, en fonction de l’évolution des algorithmes des moteurs de recherche. Néanmoins, certains types de cloaking fonctionnent toujours après de nombreuses années d’utilisation et ce, pour une raison simple : Google ne souhaite pas nécessairement allouer les moyens financiers dont il dispose, en termes de crawl de sites web, à la détection de certaines techniques de dissimulation dites frauduleuses et plus ou moins avancées.
Les différentes techniques de cloaking utilisées en SEO
Cloaking sur le User Agent : la plus risquée car la moins sophistiquée
Dès lors qu’un internaute visite un site web, le navigateur qu’il utilise envoie une chaîne de données indiquant le navigateur utilisé via l’entête HTTP de la page. Chaque visite sur un site Internet laisse ainsi une trace de son passage qui se matérialise par une chaîne de caractères indiquant, au niveau du serveur, qui a visité le site, qu’il s’agisse d’un humain ou d’un robot.
On peut donc facilement modifier son user-agent depuis son navigateur, ou depuis un autre outil comme un crawler par exemple, et se faire passer pour GoogleBot.
Voici à quoi ressemble le user-agent de GoogleBot :
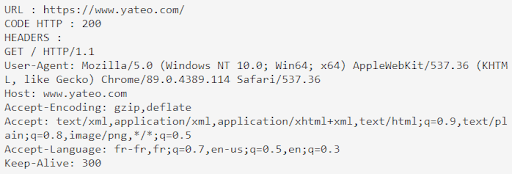
Découvrez la liste des user-agent de l’ensemble des robots d’exploration que Google utilise.
Pour faire simple, la variable PHP ci-dessous permet de récupérer la valeur du user-agent :
$_SERVER[‘HTTP_USER_AGENT’]
Si GoogleBot est détecté, on affiche tel contenu et s’il s’agit d’un internaute lambda, on affiche tel autre. On se base donc sur le user-agent du client pour mettre en place une condition qui déterminera quel type de contenu votre serveur devra afficher.
| @Younès : mettre un exemple précis de code Php dédié au cloaking sur user-agent pour illustrer |
Cloaking sur IP : la plus avancée
A l’inverse du cloaking précédent, qui se base sur le user-agent, autrement dit le nom du robot d’indexation qui a visité votre site, le cloaking sur IP s’appuie logiquement sur l’IP du visiteur. Là encore, Google nous fournit quelques informations sur les classes d’IP qu’il utilise. Néanmoins, cette liste est loin d’être exhaustive, les adresses IP de GoogleBot changeant de temps à autre. Vous pourrez en savoir plus à cette adresse : https://developers.google.com/search/docs/advanced/crawling/verifying-googlebot?hl=fr
Voici la variable Php qui permet d’identifier l’adresse IP de la machine qui se connecte au site Internet :
$_SERVER[‘REMOTE_ADDR’]
Par le biais de cette technique, on va chercher à détecter les classes d’IP utilisées par Google en vue d’afficher quelque chose de différent sur la page.
A partir de cette variable, il ne vous reste plus qu’à afficher un contenu différent quand l’adresse IP détectée correspond bien à GoogleBot. Outre le nom du user-agent et l’adresse IP et, pour être sûr qu’il s’agit bien de GoogleBot, vous pouvez ajouter une étape de vérification supplémentaire basée sur le Reverse DNS. Or, qu’est-ce que la recherche DNS inversée ? Il s’agit d’une requête DNS destinée à déterminer l’hôte correspondant à une adresse IP, à l’inverse d’une recherche DNS classique qui vise à identifier l’IP associée à un nom de domaine.
Voici un schéma explicatif :
| @Younès : mettre un exemple précis de code Php dédié au cloaking sur IP pour illustrer |
Cloaking VS obfuscation de liens : quelles différences ?
Régulièrement dans l’esprit des non-initiés, le cloaking et l’obfuscation de liens sont confondus. En pratique, il s’agit, certes, de deux techniques de dissimulation, mais elles ne servent pas le même objectif. Là où l’obfuscation cherche à masquer la présence d’un lien aux yeux de Google à des fins d’optimisation du budget crawl (Pagerank Sculpting), le cloaking vise à remplacer l’affichage d’une page, d’un contenu ou d’un lien par autre chose. Avec l’obfuscation, on masque alors qu’avec le cloaking on remplace. Par exemple, le premier affichage, visible uniquement par les internautes, contiendra simplement un formulaire, tandis que le second affichage, dédié exclusivement à GoogleBot par exemple, proposera un contenu de plusieurs milliers de mots orientés SEO. Par le biais du cloaking, on cherche essentiellement à profiter des bienfaits du SEO, à partir du contenu généré que Google apprécie fortement, sans nécessairement nuire à l’expérience utilisateur, en ne présentant aux utilisateurs qu’un formulaire afin de ne pas les distraire et de les enfermer dans un tunnel d’acquisition de leads, l’objectif étant d’avoir plus de conversions via le SEO et d’optimiser le taux de conversions via l’UX. Le cloaking peut avoir comme intérêt de réconcilier SEO et UX qui ne font pas toujours bon ménage.
Par ailleurs, l’obfuscation se fait côté client (navigateur) par le biais du JS notamment (d’autres techniques existent via le HTML par exemple), tandis que le cloaking intervient essentiellement côté serveur.
L’obfuscation, moins dangereuse que le cloaking ?
Dans les deux cas, ne nous racontons pas d’histoires ! On cherche à tromper les moteurs de recherche en vue d’améliorer le classement de son site dans leur index. Néanmoins, on considère bien souvent que l’obfuscation est “mieux accepté” et, par conséquent, moins risqué dès lors qu’on cherche à optimiser le passage des robots des moteurs de recherche en les orientant vers les pages les plus intéressantes, non seulement pour les spiders mais aussi pour les internautes. En effet, Google n’a cure d’une page Mentions Légales, inintéressante d’un point de vue sémantique, accessible la plupart du temps en lien sitewide, au même titre que les internautes qui ne la visitent quasiment jamais si l’on observe les statistiques de trafic. Ce type de pages, au même titre que les pages de formulaires, ne caractérisent pas le site en tant que tel. Elles se ressemblent même entre tous les sites ou font office de doublon avec d’autres pages déjà existantes, à l’instar des filtres en ecommerce. C’est pourquoi, il est inutile de permettre aux moteurs de passer sur ce modèle de pages qui nuisent au temps de crawl que Google ou d’autres moteurs de recherche accordent à un site Internet.


Suivez-nous