
Les sites étant de plus en plus complexes et surtout de plus en plus dynamiques, il n’est pas rare de devoir optimiser le budget crawl en désindexation des pages jugées inutiles, voire pénalisantes pour le SEO.
Or, savez-vous comment faire pour déréférencer une page web déjà présente dans l’index de Google ? Il existe plusieurs moyens de le faire, la balise canonical et la redirection 301 notamment, mais nous allons surtout nous concentrer sur l’instruction Noindex dans cet article, laquelle permet de demander à Google ou aux autres moteurs de recherche de ne plus indexer la ou les pages ayant cette mention, soit dans l’entête HTTP X-Robots-Tag: noindex, soit via la balise HTML <meta name=”robots” content=”noindex,nofollow”> à placer entre les balises <head> et </head> du code source d’une page web.
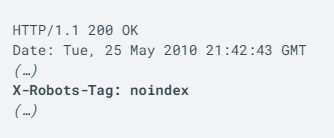
L’en-tête HTTP X-Robots-Tag
Voici à quoi ressemble un code réponse HTTP avec une instruction X-Robots-Tag qui indique aux robots d’exploration de ne pas indexer une page :
La balise Meta pour les robots
Voici à quoi ressemble la balise Meta pour les robots dans le code source d’une page web :

Aucune des deux méthodes n’est mieux que l’autre. Les deux fonctionnent très bien et permettent de désindexer une page rapidement.
À savoir : depuis quelques années le fichier robots.txt ne permet plus, via la directive Noindex: de désindexer une page déjà présente dans l’index de Google, auquel cas, vous devrez utiliser l’une des deux méthodes précédentes.
En revanche, le fichier robots.txt permet d’empêcher le crawl d’une page via la commande Disallow:. À ce titre, si la page dont vous souhaitez empêcher le crawl n’a encore jamais été indexée, le fichier robots.txt peut permettre d’empêcher que ladite page le soit.


Suivez-nous