
Table des matières
Le « robots.txt » est un fichier texte placé à la racine d’un site web et qui sera lu par les crawlers (ou robots d’exploration) des moteurs de recherche. En effet, les crawlers ont pour but d’explorer et d’analyser les pages web des sites internet dans le but de les indexer.
À quoi sert le robots.txt ?
Les webmasters souhaitent que certaines de leurs pages ne soient pas analysées par ces robots. C’est là que le fichier « robots.txt » intervient. Il permet d’indiquer aux crawlers quelles pages ils doivent ou non visiter. Ainsi les crawlers ne peuvent pas indexer ces pages et elle n’apparaîtront pas dans les résultats des moteurs de recherche. Ce fichier est le moyen de communication entre les éditeurs de page web et les robots explorateurs.
Un fichier non standardisé.

Le fichier « robots.txt » existe depuis plus de 25 ans maintenant. Il a été crée par Martijn Koster en 1994. Initialement, il rédigea le Robots Exclusion Protocol (REP) qui posait les bases du fonctionnement de ce fichier. Mais depuis, même si désormais il est devenu indispensable à tous les webmasters, il n’a jamais réellement été standardisé : c’est ce que Google a décidé de faire. Effectivement, de nombreuses fonctionnalités et syntaxes ont été ajoutées avec le temps par les différents moteurs de recherche, mais rien de commun à tous, ni d’officiel.
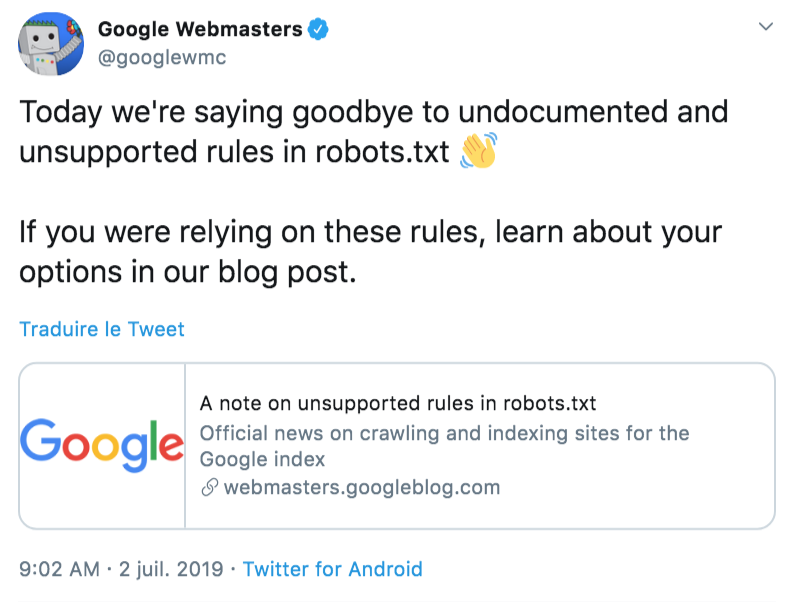
Source : Twitter @googlewmc
C’est pourquoi avec l’aide du créateur du REP et d’autres moteurs de recherche, Google se lance dans ce processus de standardisation, qui a pris effet dès le 1er septembre 2019.
Concrètement qu’est-ce qui change ?
Conjointement à cette volonté de standardisation, Google a annoncé l’abandon du support de certains tags jugés inadéquats. Notamment le « noindex ».
Le « noindex » permettait aux webmasters d’indiquer de manière active qu’une page ne devait pas être indexée par le moteur de recherche. Cependant, pour Google, cette déclaration n’a plus sa place dans le « robots.txt ».
Quelle sont les solutions alternatives ?
- La plupart des webmasters indiquaient directement dans le code HTML de la page web en question, grâce au meta tag « noindex » que l’indexage était interdit. C’est la solution de substitution la plus préconisée.
- Une autre alternative consiste à simuler une page d’erreur 404 ou 410. En effet, il est possible de renvoyer un code d’erreur HTTP 404 ou 410 manuellement à une page web. Ces codes d’erreur sont habituellement utilisés pour les pages introuvables ou vides, mais peuvent être également utilisés pour une page fonctionnelle. Ainsi, comme le moteur de recherche a pour directive de ne pas indexer les pages qui renvoient ces codes HTTP, elle restent non-indexées.
- La mise en place d’une combinaison login/mot de passe pour protéger l’accès à une page. Par ce biais, les crawlers ne peuvent pas avoir accès au contenu de la page et donc abandonnent automatiquement son indexage.
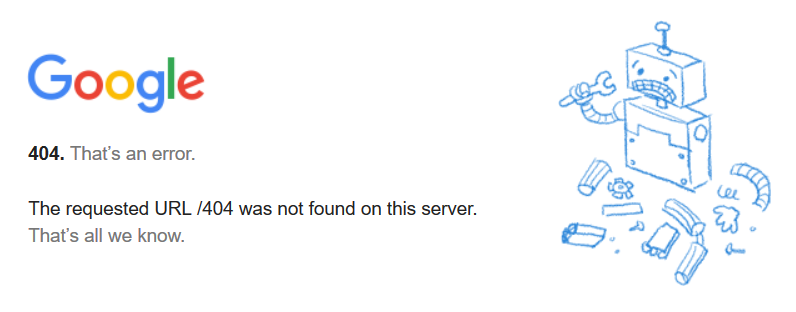
Néanmoins, ces techniques ont leurs limites. Car la page est tout de même analysée par les crawlers, même si elle ne sera pas indexée par la suite. À l’inverse du « robots.txt » qui bloque l’analyse en amont.
C’est là que la notion de « budget crawl » intervient. Un moteur de recherche alloue un « quota » de page à explorer par site web et qui pourront donc être indexées. Pour les petits sites ces techniques n’auront pas d’impact, mais pour ceux qui comptent un plus grand nombre de pages, cela peut rapidement devenir limitant.
Une autre possibilité plus radicale et ne consommant pas le « budget crawl » est l’utilisation du « disallow ». Il s’agit d’une autre instruction du « robots.txt » qui bloque totalement l’accès aux robots explorateurs. Cependant, à l’inverse du « noindex », cela ne signifie pas que l’indexage de la page est rendu impossible. Si une autre page analysée par les crawlers, interne au site ou non, pointe vers son URL, les robots pourront l’indexer.
La solution de dernier recours est d’utiliser la Google Search Console, notamment sa fonctionnalité de suppression d’URL. Celle-ci permet d’empêcher l’affichage de certaines pages de sites dont vous êtes le propriétaire dans les résultats de recherche Google. Toutefois ce blocage est temporaire et n’est effectif que pendant 90 jours. Une fois ce délai passé, vous devrez reformuler une demande de blocage.
YATEO, agence digitale parisienne, depuis 13 ans vous accompagne dans vos projets digitaux et vous aide à optimiser la performance de votre site internet. N’hésitez pas à contacter nos équipes au 0158892736 ou via le formulaire de contact disponible ici.


Suivez-nous